Social media and online social networking sites contain opinionated, inaccurate or false facts that may get refuted over time. Spread of misinformation may have confused and misled voters in the last U.S. presidential election or the Brexit referendum. To address this problem, online platforms deploy evaluation mechanisms for their users to further curate information within these platforms. For example, users can remove inaccurate contents from Wikipedia, mark a correct answer as verified in Stack Overflow and flag a story as misinformation in Facebook and Twitter.
We developed a unified computational framework [ ] that leverages the temporal traces left by the aforementioned examples of noisy evaluations to estimate robust, unbiased and interpretable notions of information reliability and source trustworthiness. The key idea is that unreliable contents are often removed quickly while reliable contents remain on platforms such as Wikipedia for a long time. Similarly, information contributed by sources which systematically spread misinformation are often removed quickly on a wide range of entries, while contents contributed by thrustworthy sources remain on a platform for a long time. By applying our framework to Wikipedia data, we are able to answer questions such as whether bbc.co.uk provides more reliable information compared to newyorktimes.com in Wikipedia entries related to the U.S politics, and at which point in time a particular Wikipedia entry, such as Barack H. Obama, was unreliable due to ongoing controversies.
Next, we focused on developing a machine learning method to detect and reduce the spread of harmful misinformation in online social networking sites through the power of the crowd and fact-checking [ ]. Given limited reviewing resources, the main question is how to prioritize questionable content. Some cases of misinformation are not identified until a large number of users have been already exposed to it. However, many cases may only have a limited impact on people and unnecessarily consume reviewing resources for fact-checking. To address these challenges, we developed a robust methodology with provable guarantees to minimize the impact of potentially harmful contents on a large number of people. Results of applying this algorithm on datasets from Twitter and Weibo suggest that our method can identify cases of misinformation earlier than alternative methods and also uses fact-checking resources more efficiently.
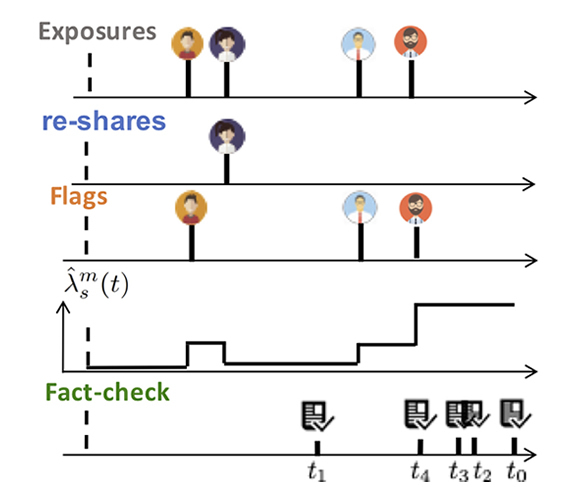
Figure: Fact checking of content on social networks using observed exposure, reshare and flag events. The rate of fact checking, $\hat{\lambda}^m_s(t)$, is updated after every observed event.
Fact-checking and removing content from social platforms are not always possible since not all potentially harmful content can be fact-checked in time. For many platforms it is still desirable to reduce circulation of such potentially harmful content. Facebook and Twitter often resort to modifying their ranking algorithms to reduce distribution of contents that present evidence of harm but are not yet fact-checked. In our next work in this series [ ], we present a probabilistic Reinforcement Learning method to reduce the impact of harmful content over a specific time horizon by modifying any existing blackbox ranking algorithm. We apply this algorithm on data from Reddit and demonstrate that modifying rankings of comments of a post can minimize the spread of misinformation and improve the civility of online discussions.