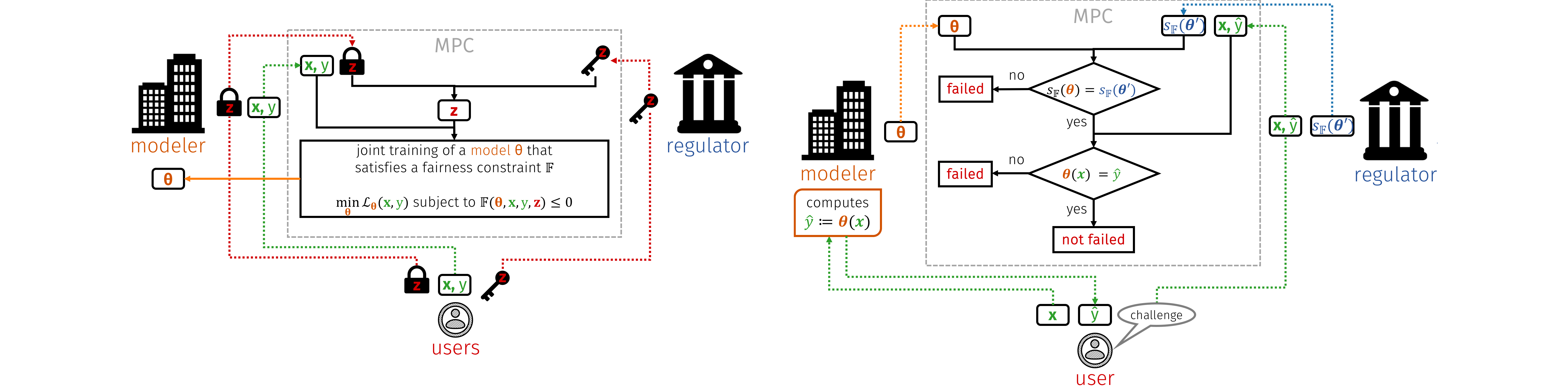
Protocols based on secure multi-party computation to learn (left) and verify (right) a fair model using only encrypted sensitive attributes; for details, see [ ].
If algorithmic decision-making processes are becoming automated and data-driven in consequential domains (e.g., jail-or-release decisions by judges, or accept-or-reject decisions in academia), there are concerns of the potential unfairness of these systems towards people from certain demographic groups (e.g., gender or ethnic groups). We aim to contribute insights and, where possible, remedies.
Forms of legally problematic discrimination are commonly divided into several categories, e.g., "disparate treatment" (or direct discrimination), and "disparate impact" (or indirect discrimination). Despite the variety of proposed solutions, e.g., "fairness by unawareness", "demographic parity", etc., most of the existing criteria are observational: they depend only on the joint distribution of predictor, protected attribute, features, and outcome, and are formulated as potentially approximate conditional independencies.
Instead, we proposed a preference-based notion of (un)fairness, which is inspired by the fair division and envy-freeness literature in economics and game theory [ ]. This definition provides a more flexible alternative to previous notions that are mostly based on parity of distributions of outcomes.
We also propose novel fairness criteria that distinguish between different causal models underlying the data, despite identical observations distributions. We present training methods to achieve fair classifiers that come with theoretical guarantees under certain regularity assumptions [ ].
Moreover, we mitigate unfairness by developing flexible constraint-based frameworks to enable the design of fair margin-based classifiers [ ]. We contribute a general measure of decision boundary unfairness, which serves as a tractable proxy to several of the most popular computational definitions of unfairness. We can thus reduce the design of fair margin-based classifiers to add tractable constraints on their decision boundaries.
Avoiding both disparate impact and disparate mistreatment is a major challenge, due to tensions that arise in the intersection of privacy, accountability, and fairness. By encrypting sensitive attributes, we show how a fair model may be learned, checked, or have its outputs verified and held to account, without users revealing their sensitive attributes, cf. the above figure and [ ].
Despite fairness definitions and mechanisms, there is a lack of ML methods to ensure accuracy and fairness in human decision-making. In this context, each decision is taken by an expert who is typically chosen uniformly at random from a pool of experts. We showed that a random assignment may result in undesirable results for both accuracy and fairness, and propose an algorithm to perform an assignment between decisions and experts that jointly optimizes for both [ ].
Finally, decisions made for humans bias the dataset labels towards those that are observed. In absence of ground truth labels, we propose to directly learn decision policies that maximize utility under fairness constraints and thereby take into account how decisions affect which data is observed in the future [ ].